Implementation Details
This page covers how Pysa actually tracks the flow of tainted data from source to sink. These implementation details affect how some functionality of Pysa works, such as source- and sink-specific sanitizers, so it is useful reading even for end users who never intend to work on Pysa itself.
This page is a subset of what is presented in the Pysa DEF CON Tutorial. Work through that tutorial for an even more complete understanding of how Pysa works.
Summaries
Pysa works by computing summaries of all functions. Summaries describe:
- Which function arguments hit sinks
- Which sources the function returns
- Which arguments propagate their taint to the return value in some way
These summaries cover the entire call graph of the function. Covering the entire
call graph means that if foo calls bar, foo's summary will include
information on sources and sinks that are reachable in bar.
Iteration
Pysa's summary inference process is iterative. Summaries must be continually
recomputed until a global fixed point is reached. The fixed point occurs when an
entire iteration is completed without any summary changing. Pysa uses a call
dependency graph to determine which functions need to be re-analyzed after a
given iteration (ie. if foo calls bar, and bar's summary changed last
iteration, foo must be reanalyzed this iteration to see if it's summary will
also change).
Source Summaries
The source portion of summaries track how data from a source is eventually
returned by a function. To compute the source portion of a summary, Pysa must
start with a model such as this one that states source returns tainted data of
type UserControlled:
def source() -> TaintSource[UserControlled]: ...
Then Pysa can analyze the source code of a function such as returns_source and
infer that it will also return taint of type UserControlled:
def returns_source():
return source()
This inference results in a summary for returns_source, which we can
conceptually think of as an inferred model like this:
def returns_source() -> TaintSource[UserControlled]: ...
Pysa's next iteration can start with that summary for returns_source, and use
it when anlyzing the code for wraps_source:
def wraps_source():
return returns_source()
From this code, Pysa can infer a model documenting that wraps_source will also
end up (indirectly) returning taint of type UserControlled:
def wraps_source() -> TaintSource[UserControlled]
Sink Summaries
The sink portion of summaries track how arguments to a function eventually flow
into a sink. To compute the sink portion of a summary, Pysa must start with a
model such as this one that states sink's parameter arg is as an
RemoteCodeExecution sink:
def sink(arg: TaintSink[RemoteCodeExecution]): ...
Then Pysa can analyze the source code of a function such as calls_sink and
infer that calls_sink's arg will also end up in a RemoteCodeExecution
sink:
def calls_sink(arg):
sink(arg)
This inference results in a summary for calls_sink, which we can
conceptually think of as an inferred model like this:
def calls_sink(arg: TaintSink[RemoteCodeExecution]): ...
Pysa's next iteration can start with that summary for calls_sink, and use it
when anlyzing the code for wraps_sink:
def wraps_sink(arg):
calls_sink(arg)
From this code, Pysa can infer a model documenting that wraps_sink's arg
will also end up (indirectly) reaching an RemoteCodeExecution sink:
def wraps_sink(arg: TaintSink[RemoteCodeExecution]): ...
Taint In Taint Out (TITO) Summaries
Pysa summaries also track how tainted data propagates from function arguments
into that function's return value. This is known as Taint In Taint Out (TITO).
When computing the TITO portion of summaries, Pysa does not need to start from a
model at all (however, an explicit TaintInTaintOut
model can be written, if desired). Pysa can
simply start by looking at the source code for a function like tito and
inferring that it's arg parameter gets propagated to the return value of the
function:
def tito(arg):
return arg
This inference results in a summary for tito, which we can conceptually think
of as an inferred model like this:
def tito(arg: TaintInTaintOut): ...
Pysa's next iteration can start with that summary for tito, and use it
when anlyzing the code for wraps_tito:
def wraps_tito(arg):
return tito(arg)
From this code, Pysa can infer a model documenting that wraps_tito's arg
will also end up (indirectly) propagated to the return value of the function:
def wraps_tito(arg: TaintInTaintOut): ...
Emitting Issues
An issue indicates that Pysa has found a flow of data from a source to a sink (for any source-sink pair specified in a rule). Issues occur in the function where summaries indicate data from a source is returned from one function and is then passed into another function whose argument reaches a sink. This means issues often unintuitively occur in a function that is somewhere in the middle of the flow from source to sink.
Continuing the previous examples, Pysa can use the summaries computed for
wraps_source, wraps_sink, and wraps_tito to identify an issue in
find_issue:
def find_issue():
x = wraps_source() # x: TaintSource[UserControlled]
y = wraps_tito(x) # y: TaintSource[UserControlled]
wraps_sink(y) # Issue!
The summary for wraps_source tells Pysa the return value is tainted data of
type UserControlled, and thus x is marked as UserControlled. The summary
for wraps_tito tells Pysa that tainted data passed in through arg will be
propagated to the return value, and thus y is marked with the same taint as
x (UserControlled). Finally, the summary of wraps_sink tells Pysa that
data passed into arg eventually reaches a sink of kind RemoteCodeExecution.
Assuming we have a rule that says we want to find flows from UserControlled
to RemoteCodeExecution, Pysa will then emit an issue on the line where
wraps_sink is called with the UserControlled data in y.
Visualizing Issues
Visualizing the flow of data in a given issue ends up looking something like this:
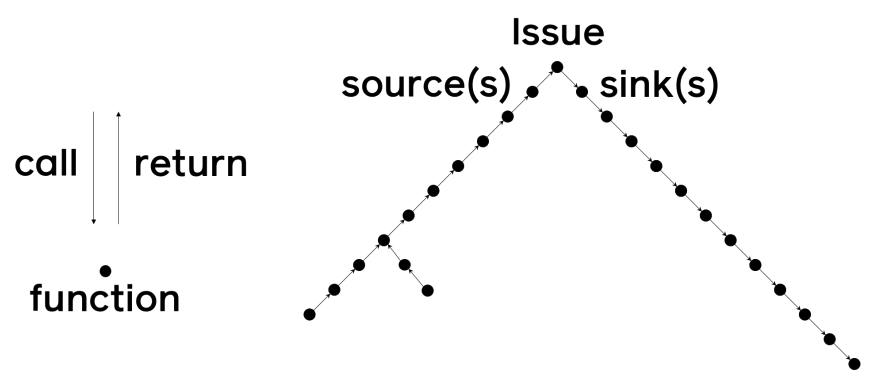
Overall, the traces form an inverted V, with sources and sinks connecting at the apex. There can be multiple sources for an issue, because two different sources can both end up combined into a single return value for a function. Similarly, there can be multiple sinks because a single argument to a function could be passed into two different sinks.
The TITO process appears as a loop in this visualization, because data passed into a TITO function will always end up back in the original function via the return value of the TITO function.